
「森羅プロジェクト」はWikipediaの知識を拡張固有表現のフレームを利用して多くの方の協力の元で構造化しようというプロジェクトです。
Wikipediaの構造化 & RbCC
クラウドソースによって構築・更新が行われているWikipediaには、他の百科事典にはない、圧倒的な量の項目が収録されています。しかしながら、これらの項目は、あくまで人が閲覧するための構造しか持っておらず、機械可読な形で表現されているとは言えません。
「森羅プロジェクト」ではこのようなWikipedia項目を、機械可読な構造に変換する「構造化」を目指しています。
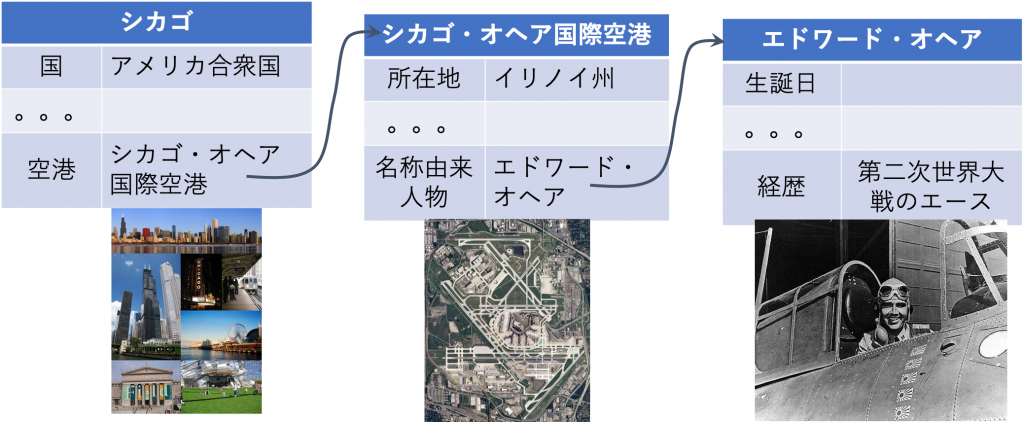
具体的には、言葉の分類体系である拡張固有表現の各カテゴリーに設定されている属性情報をWikipedia記事中からの取得を行う評価型ワークショップを開催し、その結果を統合することで構造化された知識源を実現します。このやり方を「Resource by Collaborative Contribution (RbCC)」と名付け、多くの方の協力で進んでいくプロジェクトになっています。
分類データ
拡張固有表現に対してWikipedia記事を分類したデータを公開しています。下記のリンク先ページにて、個人情報をご入力頂くとダウンロード出来ます。
構造化サンプルデータ
最新版の構造化サンプルデータです。拡張固有表現カテゴリー35種類に対して、数百件ずつのアノテーションデータが格納されています。その他、プロジェクトに関連するデータも公開しています。
評価型ワークショップ
過去に行われた評価型ワークショッププロジェクトです。
- 森羅2018プロジェクト
- 森羅2018では、5種類の拡張固有表現カテゴリーについて、それぞれのカテゴリーに分類されたWikipedia記事の文書中から、属性値を抽出する抽出タスクを評価型プロジェクトとして開催しました。
- 森羅2019プロジェクト
- 33種類の拡張固有表現カテゴリーについて、Wikipedia記事の文書中の、それぞれのカテゴリーの属性値に対応する記述部分にアノテーションを行うタスクを評価型プロジェクトとして開催いたしました。