
公開データ入手フォーム
- 下記のサイトで必要事項を記入すると、データへのリンクが記載されたメイルが受け取れます。
本データに関して、言語処理学会第30回年次大会において発表を行います。データを使われた方は、HPと共に下記の通りにお願いします。
関根聡, 安藤まや, 後藤美知子, 鈴木久美, 河原大輔, 井之上直也, 乾健太郎. ichikara-instruction: LLMのための日本語インストラクションデータの構築. 言語処理学会第30回年次大会(2024)
公開データ一覧
以下のデータはすべてCC-BY-NC-SAにて公開しております。
- ichikara-instruction-003-(002,003)-1.json
- 2024/3/7公開:2023/12/23公開に追加する形の1999件のインストラクションデータ
- 合計で4802件のデータ
- Distribution20241221_all.zipに4802件がまとめてあります
- ichikara-instruction-003-001-(1,2.1,2.2,5.1,5.2).json
- 2023/12/23公開:2903件のインストラクションデータ
- version 002-002の1003件を含んでいます(が高品質になっています)
- ichikara-instruction-002-002.json
- 2023/11/3公開:1003件のインストラクションデータ
- version 002-001の50件を含んでいます
- ichikara-instruction-002-001.json
- 2023/9/25公開:50件のインストラクションデータ
Version-003-002,003はVersion-003-001に対する追加ファイルで1999件のデータが含まれています。両方を合わせてご利用ください。
Version-003-001では下記の点に対処し、最初に公開した1003件もほぼ全面的に書き直し、より高品質になっております。
Version-002-002(1003件のデータ)について少し詳細をお知らせします。このデータはデータ作成における最初のサイクルでしたので、作成方法やルールがまだ未熟でした。実は、公開前には約1500件くらいができていたのですが、明らかに品質不充分な500件を除外して公開しました。その後、この公開している1003件も精査し直したところ、やはり再構築した方がいいものがあるという判断をし、除外した500件と共に1003件の不十分なところも、公開以降に再度作成し直しております。不完全なデータであること、ご了承ください。
いただいたコメント
- 共同研究に参加していただいている「マネーフォーワード」様のVersion-003-001データを利用したhououシステムの評価結果です。システムはこちらで公開されています。(https://huggingface.co/moneyforward/houou-instruction-7b-v2)
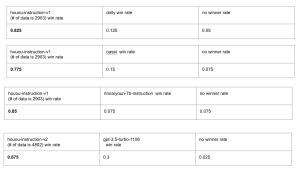
- 共同研究に参加していただいている「ストックマーク」様のブログ記事です。(Version-002-002データを利用)
今回行った二つの評価では、「LLMのための日本語インストラクションデータ作成プロジェクト」のデータセットを用いてInstruction tuningを行なったモデルの性能が最も高いという結果が得られました。 このデータセットで現時点で利用可能なデータは他のデータセットと比べるとまだ少ないにも関わらず、最も高い性能を示したことは、最終的なモデルの性能にはデータの質が重要であることが示唆されます。
- 共同研究に参加していただいている「オルツ」様からの情報です。(Version-002-002データを利用)
すでにDollyなどでFTしているLLM(LHTM-OPT)に、今回公開した1003件のデータ(同時により少ない他のデータも)を入れてFTしたところ、Rakudaベンチマークでかなり精度改善が確認でき、現在公開されている9/25のリーダーボードのGPTを除いたシステムでは最高性能になりました。
https://prtimes.jp/main/html/rd/p/000000053.000111359.html
- 共同研究に参加していただいている「マネーフォーワード」様のプレスリリースです(Version-002-002データを利用)
https://corp.moneyforward.com/news/release/corp/20231206-mf-press-1/
下記は、データをご覧になった皆様からのコメントです(抜粋)
-
私の調べていた範囲では、インストラクションデータはかなり不自然な質問・回答を含んだ英語データの翻訳版しか見たことがなかったので、このクオリティのデータが1万件自由に使えるとなると確実に嬉しいと思いました。やはり、初めから日本人が日本語で書くと色々と(談話構造や文化的な部分など)自然なデータができますね。
-
全体的に素晴らしいと思います。こんな感じのデータが日本語にあればいいなと思っていました。
-
アノテーションの質はほんとうにいいと思います。機会があったらアノテータさんたちにすばらしいとお伝えください
(免責事項)制作者は、利用者が利用者自身又は第三者に与えた損害について、一切の責任を負わないものとする。また、本データのサービス提供の遅延、中断又は停止により利用者又は第三者が被った損害について、制作者は一切の責任を負わないものとする。制作者は、予告なしに、本データの運営を停止若しくは中止し、又は本データに掲載される情報の全部若しくは一部を変更する場合がある。
(著作権)本データの著作権は理化学研究所に属します。